When you’re scanning the IPv4 space for TLS certificates, the bottleneck isn’t usually the SYN sweep or the TLS handshakes individually. It’s the interaction between them, and the standard tooling doesn’t model that interaction.
The canonical research pipeline is ZMap piped through ZTee into ZGrab2. ZMap fires SYNs at a configured L4 rate. ZGrab2 reads verified hosts off the pipe and runs TLS handshakes at a configured worker count. They share an interface, a kernel, and an uplink, but they don’t share a rate budget. The result on dense CDN ranges is that ZGrab2’s certificate traffic can dwarf ZMap’s SYN stream, with no mechanism for the L7 surge to throttle the L4 cannon. On global anycast prefixes the same dynamic causes something more interesting: per-AS scanner detection at the CDN that neither tool would trigger alone.
I built LYNX to test a hypothesis: if you collapse the pipeline into one process with a unified rate governor, you get better wall-clock time on dense ranges, better resilience under CDN scrutiny, and richer output, without sacrificing the stateless properties that make ZMap correct at scale.
This post is about why that hypothesis held up across 2.7 million addresses of benchmarking, what the architecture looks like, and where it doesn’t pay off.
Why I built this
The first version of this work wasn’t LYNX. It was MIMS, a stateful Layer 4 scanner I built earlier in the year, before I’d internalized why ZMap’s architecture looks the way it does. MIMS opened a real connect() to every IP in the target range, ran TLS, parsed the certificate. On cloud instances at 50,000 concurrent connections it benchmarked 12-42% faster than ZGrab2. I thought I’d found something.
Then I tried it on a /12.
nf_conntrack filled in seconds. The kernel started dropping connections silently. Adding a “subnet circuit breaker” that skipped /24s after 250 consecutive failures helped, but it was treating a symptom. The real problem was that I’d built a tool that scaled inversely with the size of the problem it was supposed to solve. Every dead address I touched cost me kernel state I didn’t have.
The instinctive fix was to bolt on stateless discovery: run ZMap, feed its host list into MIMS, done. But that’s just the existing pipeline with extra steps. The interesting question, the one I couldn’t shake, was whether the separation between discovery and extraction was load-bearing or accidental. The pipeline enforces it because the two phases are different programs. What if they didn’t have to be?
Once I started pulling on that thread, the bandwidth coupling problem fell out of it. If discovery and extraction share a process, they can share a rate budget. If they share a rate budget, the L7 surge problem solves itself. If the L7 surge problem solves itself, the per-AS scanner detection on anycast ranges becomes addressable in software rather than a network-layer fact you have to live with.
LYNX is what the second draft of MIMS turned into once I took that question seriously.
Background, briefly
For readers new to this space: ZMap is the standard stateless scanner. It transmits raw TCP SYN frames via AF_PACKET, bypassing the kernel TCP stack so no nf_conntrack entries are created. It encodes a cryptographic cookie into each SYN’s source port and sequence number, recomputes the expected cookie when SYN-ACKs arrive, and discards anything that doesn’t match. ZGrab2 is the application-layer companion: it reads ZMap’s host list, opens standard TCP connections, and runs full TLS handshakes to extract X.509 certificates. The two are connected by a deduplication filter (ZTee) and run as separate processes.
This pipeline is well-validated and powers Censys’s continuous Internet measurement infrastructure. Everything I describe below is built on the foundations the ZMap and ZGrab2 teams established. The question is what changes when you put both layers in one binary with a shared rate budget.
The bandwidth coupling problem
ZMap’s token bucket caps SYN packets per second. ZGrab2’s worker count caps concurrent TLS handshakes. Both are reasonable in isolation. They miss the same thing.
A SYN frame on the wire is 54 bytes. A TLS handshake including certificate transmission is several kilobytes. On a /12 with 67% host density, ZMap at 5,000 pps generates roughly 2.1 Mbps of L4 traffic. ZGrab2’s 500 workers feeding off the resulting host list generate inbound certificate traffic that can exceed 200 Mbps. These two flows share a NIC, a kernel buffer, and an uplink. They do not share a budget.
In normal operation this is fine because the operator picks rates that fit the link. The interesting case is when something on the path is watching for combined traffic patterns. CDNs are.
On Cloudflare’s 104.16.0.0/13 anycast range I saw a measurable certificate deficit running LYNX in standard concurrent mode versus the pipeline: 54,424 certs vs 56,654, a gap of ~2,230. The pipeline isn’t structurally smarter here. It’s just slower in a way that matters. ZGrab2’s 500-worker pool against a ZMap host list that grows gradually via ZTee never produces the same burst intensity as a single binary firing 20,000 TLS workers the moment the first SYN-ACKs verify. The CDN’s per-AS scanner detection latches onto the combined pattern and silently drops inbound SYNs from the scanning IP. Discovery degrades retroactively while extraction is still running.
This is the bandwidth coupling problem. Two independent rate limits cannot model the joint behavior the network actually sees.
The fix in LYNX is a single Arc<AtomicI64> token bucket shared across the SYN cannon and every TLS worker. The cannon deducts 54 bytes per SYN. Each TLS worker deducts ~10 KB at connection initiation. Both deductions hit the same counter via compare_exchange_weak, lock-free, no mutex. When TLS workers are active and consuming tokens, fewer remain for the cannon, which yields naturally on consume_l4. The math is:
| |
No cross-thread messaging. No coordinator process. The atomic counter is the coordinator.
The two-phase --anycast-mode is the operational complement. On global anycast ranges where concurrent L2+L7 from one IP triggers detection, LYNX runs a pure SYN sweep first (zero TCP sessions, indistinguishable from background scanning), waits for traffic to drain, then runs TLS extraction sequentially against the verified host list. This recovers full certificate yield on Cloudflare to within four certificates of the pipeline (57,103 vs 57,107, 0.007% delta), and consistently anchors discovery above 322,200 hosts across runs where the pipeline dropped as low as 300,295 under BGP instability.
Architecture
LYNX is one process with three concurrent units and two shared primitives.
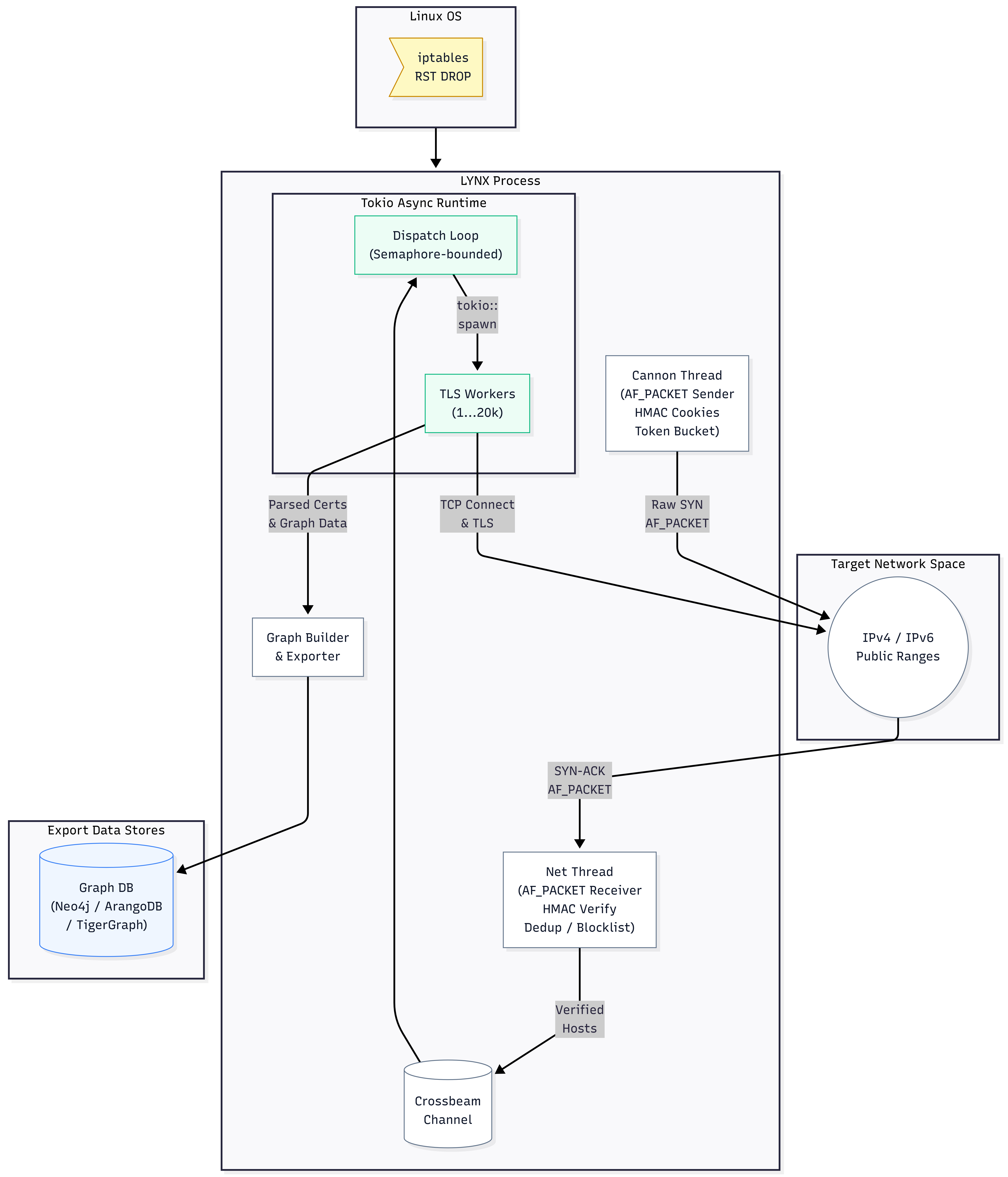
The Cannon is a dedicated OS thread that opens an AF_PACKET SOCK_RAW socket and transmits raw TCP SYN frames directly to the NIC. Each frame is a 54-byte stack buffer ([u8; 54] for IPv4, 74 for IPv6). The buffer is reused across iterations; only per-target fields are overwritten before each sendto. Zero heap allocation in the send loop. CIDR iteration is XOR-shuffled, not sequential, so traffic distributes uniformly across the target’s router infrastructure rather than concentrating on contiguous /24s.
The Net thread is a second OS thread reading inbound frames from the same NIC via another AF_PACKET socket. For each candidate SYN-ACK it runs three checks: HMAC verification first (recompute the expected cookie from src_ip || port, compare to echoed fields, ~200 ns per packet), then blocklist filter, then deduplication. Verified hosts are sent to the TLS pool via crossbeam::bounded::try_send. If the channel is full the host is dropped rather than blocking. This is deliberate. Blocking the Net thread stalls recvfrom, which lets the kernel’s NIC receive buffer overflow, dropping frames at the driver level. Dropped TLS work is recoverable via the retransmit bitmap; dropped NIC frames are not.
The Tokio TLS pool is a single async dispatch loop, not N tasks blocking on recv. The dispatch loop calls semaphore.acquire_owned().await before spawning each TLS worker, suspending cooperatively when all --tls-workers permits are in use. The permit moves into the spawned task closure as _permit and drops automatically when the task returns.
A naive design here gets this wrong. Spawning N=10,000 tasks each doing spawn_blocking(|| channel.recv()) blows past Tokio’s blocking thread pool ceiling (default 512), leaving 9,488 tasks permanently queued and never reading from the channel. The channel fills, the Net thread’s try_send starts dropping verified hosts, and you discover the bug only by noticing your scan yield is mysteriously lower than ZMap’s. The single dispatch loop with a semaphore is the correct shape for this problem.
Why OS threads, not Tokio tasks, for L4
The Cannon and Net threads are dedicated OS threads, not Tokio tasks, because both rely on blocking syscalls that must not stall the async runtime.
The Cannon’s hot loop is: check token bucket, build frame, sendto, repeat. The Net thread’s hot loop is: recvfrom with 100 ms timeout, parse, verify, forward. Both sendto and recvfrom are blocking. Putting them inside a Tokio task without spawn_blocking blocks one of Tokio’s async worker threads for the duration of every call, starving every other task on that thread. With two such threads running continuously, the TLS pool is effectively dead.
spawn_blocking would technically work but consumes two slots from the blocking thread pool continuously and adds scheduler overhead on every syscall. For threads whose entire job is to call blocking I/O in a tight loop, dedicated OS threads are the correct primitive. Async is the wrong abstraction for this layer.
iptables, automated
The Cannon bypasses the kernel TCP stack, so the kernel has no record of any outgoing SYN. When SYN-ACKs arrive, the kernel emits RST to terminate the unexpected connection, which reaches the target server before the Net thread can verify and act. Without RST suppression every SYN-ACK gets killed in flight.
ZMap’s solution is documented as a manual prerequisite:
| |
In practice this is one of the most common ZMap operator errors. Forget it and the scanner appears to run normally but discovers zero hosts. Silent failure.
LYNX manages the rule itself via a Rust Drop guard:
| |
The atomic flag means LYNX never removes a rule it didn’t add, so pre-existing operator firewall configuration stays intact. SIGKILL is the one case where Drop doesn’t run; the next invocation detects and removes the residual rule before adding its own.
This isn’t a headline feature. It’s the kind of operational detail that determines whether a tool gets used twice.
Anycast mode: when concurrency hurts
The default LYNX mode runs discovery and extraction concurrently. On dense unicast CDN ranges (Akamai NA, Akamai EU) and most cloud ranges, this is the design’s whole point: TLS workers are dispatched to early-discovered hosts before the cannon finishes the range, capturing responses from servers whose idle-connection timers would otherwise expire during the pipeline’s inter-tool handoff.
On Cloudflare’s 104.16.0.0/13 it backfires. As covered above, the joint L2+L7 burst from one IP triggers per-AS scanner detection. The CDN drops inbound SYNs while extraction is still running, and discovery degrades retroactively.
--anycast-mode runs two sequential phases:
- Phase 1: pure SYN sweep. TLS disabled. Zero TCP sessions opened. Cooldown extended to 20 seconds for BGP-shifted SYN-ACKs from distant PoPs. Verified hosts collected in memory.
- Phase 2: TLS only. Cannon fully stopped, all SYN-ACK traffic drained. TLS workers reduced to 5,000 (tuned for local hardware buffer limits). The CDN does not conflate sequential Phase 2 traffic with the earlier sweep.
The trade-off is wall time. On Cloudflare, anycast mode takes 3m 24s vs the pipeline’s 2m 02s. The pipeline is faster here because it’s structurally similar to anycast mode (separated phases) without the explicit phase boundary.
The advantage anycast mode does provide is consistency. An identical pipeline run during testing dropped to 300,295 verified hosts and 53,160 certificates under BGP instability, a loss of over 21,000 hosts and 3,900 certificates attributable entirely to network variance during concurrent execution. LYNX in --anycast-mode anchored at 322,200+ hosts across every repeated run. Two-phase isolation prevents extraction variance from corrupting the discovery baseline. The pipeline cannot replicate this property structurally.
For operators where wall time matters more than run-to-run consistency, the pipeline wins on anycast. For operators where structural completeness matters, anycast mode is the right tool.
Benchmarks
Five ranges, three continents, all measured on the same Dell G15 laptop over 802.11ac WiFi at 5,000 pps base rate (10,000 pps retransmit), against the same ZMap+ZTee+ZGrab2 pipeline command. Everything is end-to-end wall clock including retransmit passes and cooldown.
| Range | Density | LYNX Certs | Pipeline Certs | LYNX Time | Pipeline Time | Speedup |
|---|---|---|---|---|---|---|
| Akamai NA /12 | 66.9% | 384,875 | 381,827 | 4m 20s | 7m 34s | 1.75x |
| DigitalOcean /12 | 2.91% | 26,027 | 25,856 | 5m 31s | 4m 27s | Pipeline 1.23x |
| Akamai EU /13 | 56.8% | 131,921 | 130,112 | 2m 28s | 3m 47s | 1.53x |
| Alibaba /15 | 5.27% | 6,301 | 6,315 | 52.79s | 1m 35s | 1.80x |
| Cloudflare /13 (std) | 61.2% | 54,424 | 56,654 | 2m 20s | 2m 33s | 1.09x |
| Cloudflare /13 (anycast) | 61.5% | 57,103 | 57,107 | 3m 24s | 2m 02s | Pipeline 1.67x |
Why density predicts speedup
The relationship between host density and LYNX’s time advantage isn’t accidental, it falls out of the architecture.
In the pipeline, total time decomposes roughly into:
| |
ZGrab2 begins consuming hosts as ZTee delivers them, but ZMap’s sweep must complete before the last hosts reach ZGrab2, so the second term still dominates on dense ranges where extraction is most of the work. In LYNX, the same scan decomposes to:
| |
Because the two phases run concurrently, the dominant term is whichever one is longer, not their sum. The drain term is the cooldown after the cannon stops, typically 7-8 seconds.
Two factors determine which architecture wins. Density sets how much extraction work exists per unit of sweep work, high density means many TLS tasks per probed IP, which favors concurrent execution. Range size sets the absolute duration of the sweep, a longer sweep gives the concurrent extraction more time to make progress before the cannon finishes, amplifying the head-start.
The two interact. Akamai NA wins big (1.75x) because it’s both dense and large. Alibaba wins bigger (1.80x) despite low density because it’s so small that the pipeline’s fixed handoff cost becomes a large fraction of total time. DigitalOcean loses (pipeline 1.23x) because it’s both sparse and large, the worst combination for LYNX: most probes generate no TLS work, so the extraction phase finishes quickly regardless of when it started.
This also predicts where the architecture stops paying off. Below ~3% density, LYNX is structurally slower. Above ~5% density on any range size, LYNX wins. The boundary isn’t sharp because TLS success rate (the fraction of verified hosts that actually negotiate TLS) varies by network and shifts the equation. But the framing holds: this is a tool optimized for dense ranges. On sparse VPS sweeps, use the pipeline.
Some observations
The speedup tracks density on dense ranges. Akamai NA at 66.9% gets 1.75x. Akamai EU at 56.8% gets 1.53x. The mechanism is the head-start: on dense ranges, most probed IPs generate TLS work, and starting that work concurrently with discovery rather than sequentially compounds in proportion to host count. On Akamai NA, by the time the pipeline’s ZMap phase finishes its ~3m 30s sweep, LYNX has already been running TLS extraction for over two minutes against early-confirmed hosts.
Sparse ranges go to the pipeline. DigitalOcean at 2.91% density: the pipeline wins 1.23x. This isn’t surprising. With only 30,534 live hosts out of 1,048,576 probed, the SYN sweep finishes quickly regardless of architecture, making the pipeline’s inter-tool handoff cost small relative to total time. LYNX still extracts 171 more certificates and produces a real-time identity graph the pipeline doesn’t, but on raw wall-clock the pipeline is genuinely better here. Anyone optimizing for throughput on sparse ranges should use the pipeline.
Alibaba’s 1.80x is interesting. Same low-ish density as DigitalOcean (5.27%), but LYNX wins decisively. The reason is range size: the /15 has only 131,072 addresses. The SYN sweep finishes in seconds, and the 91% TLS success rate means almost every verified host generates a TLS task. The pipeline pays its full inter-tool handoff cost against a very fast sweep, which makes the absolute overhead a larger fraction of total time.
Identical extraction quality. The 44.3% TLS success rate on Akamai EU appears for both LYNX and the pipeline. The 91.0% vs 91.4% on Alibaba is statistical noise on transpacific routes during the measurement window. Whatever LYNX is doing differently isn’t changing what gets extracted, just how fast.
The honest read of the Cloudflare standard-mode 1.09x is that it’s the wrong mode for that range. The pipeline isn’t actually 9% slower than LYNX in any meaningful sense; it’s just less aggressive in a way that incidentally avoids the CDN trap. The right comparison on Cloudflare is anycast mode vs pipeline, where the pipeline is genuinely faster (1.67x) and LYNX trades that speed for better consistency.
Net certificate advantage across non-anycast ranges: +5,014. LYNX never produces fewer verified hosts than the pipeline on any tested range.
Identity graph output
The pipeline produces flat JSON: one record per certificate, written as each ZGrab2 worker completes. LYNX produces a deduplicated identity graph in real time, built concurrently with TLS extraction via a separate tokio::sync::mpsc channel from workers to the graph builder.
Eight node types: IP, Certificate, Domain, CA, Organization, PublicKey, ASN, ScanRun. Seven edge types: SERVES, ISSUED_BY, BELONGS_TO, OWNED_BY, USES_KEY, IN_ASN, SEEN_IN_RUN. Certificate and PublicKey nodes are deduplicated by SHA-256 fingerprint. A certificate served by 50,000 IPs is one node with degree 50,000, immediately visible as a hub rather than buried in a 50,000-row join.
By the time the last TLS worker finishes, the complete graph is already assembled. Zero additional wall-clock cost. Output goes to nodes.json / edges.json, plus optional Gephi CSV, Graphviz DOT, and direct Neo4j / ArangoDB / TigerGraph import bundles via --graph-db-export.
With --history-merge, LYNX tracks the certificate each domain serves across successive scan runs and emits three classes of history events:
CertRotation: the domain serves a new certificate fingerprintCAMigration: the new certificate is signed by a different CASuspiciousReplacement: both the CA and the public key changed simultaneously, which is a signal worth investigating
This is a feature category the pipeline produces no equivalent of at any speed. Whether it’s useful depends on what you’re using the data for. For inventory-style use cases, flat JSON is fine. For supply chain analysis, certificate reuse research, or longitudinal tracking, the graph form pays for itself.
What’s not in v1
A few honest gaps.
No forge_socket. The original ZMap paper described a technique for injecting an already-acknowledged L2 connection directly into a kernel socket in ESTABLISHED state, eliminating the second TCP handshake on the L7 side. The modern Linux equivalent is TCP_REPAIR. I evaluated it and decided against it for v1: TCP_REPAIR requires CAP_NET_ADMIN in addition to CAP_NET_RAW, the interface differs across kernel versions, and the gain is one RTT against a TLS handshake that costs 1-2 RTTs anyway. On a 50ms-RTT target that’s a 33-50% per-host reduction, which is real. The cost is kernel-version-specific code paths and a more fragile build target. Worth doing in a future release for controlled datacenter deployments where kernel version is fixed and the elevated privilege is already required.
Linux only. AF_PACKET and iptables are Linux-specific. macOS or BSD support would mean replacing both with BPF and an equivalent firewall API. Non-trivial and out of scope for v1.
WiFi ceiling. All benchmarks ran on shared 802.11ac. Datacenter Ethernet would give lower variance and support higher rates. The numbers reported are what a single laptop on consumer WiFi can do, which is a useful baseline but not the architecture’s ceiling.
Privilege requirement. The previous generation of this work (MIMS) ran without elevated privileges in any container, because it used standard connect() throughout. That was a genuine deployment advantage I gave up to get the nf_conntrack-free architecture. LYNX requires root or CAP_NET_RAW + CAP_NET_ADMIN and excludes restricted container environments. The privilege-free design and the scalability ceiling were the same architectural choice; you can’t have both.
What I’d build differently in v2
Limitations are about what the current code doesn’t do. This section is about what I now think the architecture itself got wrong, after living with the design through five benchmark ranges and external review.
The unified token bucket needs sub-buckets. A single global bucket enforces an aggregate ceiling, which solves the bandwidth coupling problem at the machine level. It does not solve it at the network level. On a scan touching three CDNs simultaneously, all three see the same source IP, but only one of them needs to throttle. The current design forces all of them to share a single rate, which is conservative in a way that costs throughput. A v2 should partition the token bucket by destination AS, refilled from a parent ceiling, so per-AS scanner detection can throttle only the affected slice of the scan rather than the whole thing.
The iptables guard is the wrong primitive. Shelling out to iptables works but is fragile across distros (nftables migration, Debian’s iptables-nft wrapper, RHEL’s firewalld). A small eBPF program attached to the egress path would be cleaner: drop kernel-generated RSTs only for connections matching the scan’s session secret, leave everything else alone. This also removes the need for the atomic flag that prevents removing pre-existing rules, eBPF programs are scoped to the loading process and disappear when it does. The cost is a kernel version floor (roughly 5.10+) and a more involved build, but the correctness story is much better.
The identity graph builder should be a separate process. Right now it runs in-process via tokio::sync::mpsc, which means a graph builder bug or memory pressure event takes down the whole scan. For multi-machine distributed scanning (a /8 partitioned across N nodes), the graph builder also becomes a coordination problem: each node assembles its slice in isolation, and a final cross-partition deduplication pass merges Certificate and PublicKey nodes by SHA-256. Separating the builder into its own process now makes that future work cleaner. It also opens the door to streaming graph updates to a database during the scan rather than batching at the end.
None of these are urgent. v1 ships and benchmarks well. But if I were starting v2 today, these are the three threads I’d pull on first.
Closing
The thing I find most interesting about this project isn’t the speedup numbers, it’s the consistency story on Cloudflare. The pipeline architecture cannot structurally guarantee that the discovery baseline survives extraction load, because they share the network path with no isolation. Two-phase mode in LYNX guarantees it because Phase 1 finishes before Phase 2 starts. That’s a property the operator gets for free, and it took a single-binary architecture with a unified rate governor to make it expressible.
I’m currently exploring industry roles in network security and Internet measurement. If your team works on this kind of problem, I’d be glad to talk: syedanwaruddin08@gmail.com.
Incorporated architectural feedback from David Adrian, who pointed out unified L4+L7 bandwidth governance as the differentiator worth leading with. The framing of this post owes a lot to that observation.
Source code is private. Available for review on request from companies and researchers, reach out at the email above. © 2026 Syed Anwaruddin. All rights reserved.